
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- AI
- 무상태
- 오블완
- 3티어아키텍처
- 12factorapp
- 쳇지피티
- xmlschema
- 블루그린배포
- Python
- web crowling
- 웹크롤링
- 포트바인딩
- 레이어패턴
- 책임분리
- DALL-E
- ci_cd
- 티스토리챌린지
- MSA
- JSON
- OpenAI
- chatGPT
- 클라우드네이티브
- 웨크롤링
- java17
- 티어구조
- chaosengineering
- temurin
- WSL
- 카나리배포
- API
- Today
- Total
Nacho
(Python) Web Crowling 웹크롤링 (멜론 차트 TOP 100) 본문

멜론차트를 데이터프레임으로 만들어보자..!
우선 라이브러리를 불어온다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
pandas : 데이터를 데이터프레임으로 만든다.
requests : 파이썬에서 명령어로 서버에 요청을 보내는 역할
BeautifulSoup : requsts 로 받아온 html의 parsing을 위한 라이브러리
Melon Top 100 사이트는 서버에 json 형태의 데이터를 요청하여 정보를 업데이트하는 동적사이트가 아닌,
html을 다시 받아오는 정적사이트 형태이다. 따라서, BeautifulSoup을 이용하여 원하는 데이터를 parsing 해줄 것이다.
멜론 차트 TOP 100

개발자도구 network 탭에서 htm 파일을 받아오는 url을 확인 할 수 있다.
url = 'https://www.melon.com/chart/index.htm'
headers = {
'User-Agent': "User-Agent"
}
url과 header를 지정한다. melon 사이트는 'User-Agent' 값을 통해서 사용자의 올바른 접근인가를 판가름한다.
따라서 'User-Agent'을 값을 해더에 추가해줘야한다. 'User-Agent' 값은 개발자도구 network 탭 header에서 확인 가능하다.
html 요청받기
response = requests.get(url, headers=headers)
이전에 지정한 url과 header를 이용하여 Get 형태로 Melon 서버에 html을 요청한다.
<Response [200]>
정상적으로 html을 받았다면 200번대 값을 리턴 받는다.
html에서 원하는 데이터 찾기.
dom_list = BeautifulSoup(response.text, 'html.parser')
우리는 Melon Top 100의 곡제목과 가수명을 가져오고 싶다.
그렇다면 해당 정보가 어디있는지 알아야 한다.
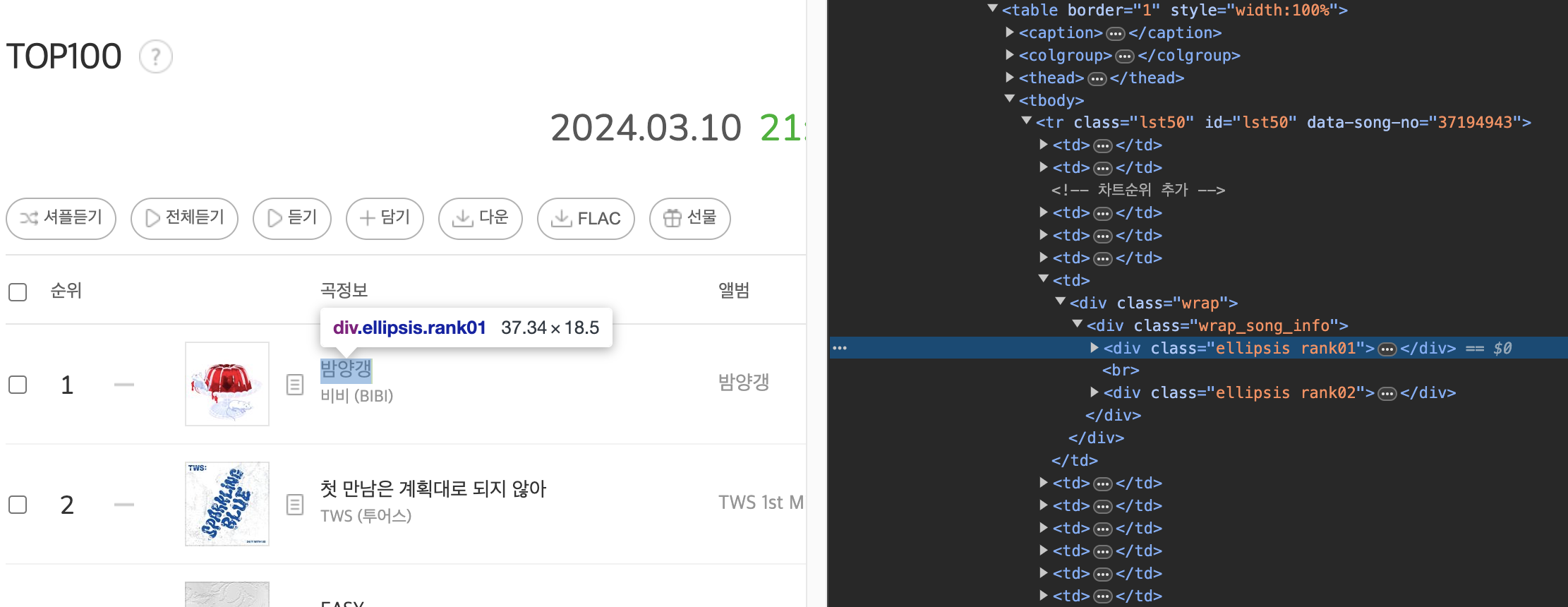
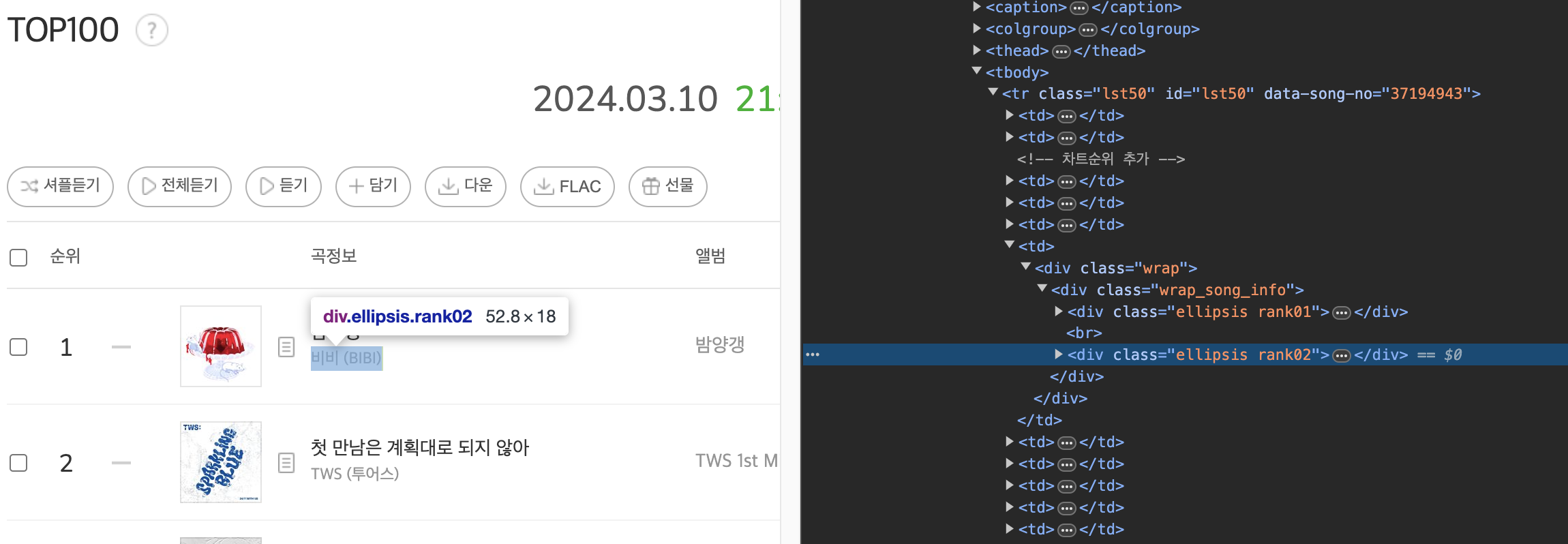
개발자 도구를 통해서 우리가 원하는 값을 어렵지 않게 찾을 수 있다.
Melon Top 100 노래 전부는 lst50 과 lst100 클래스로 나뉘어있고,
제목은 ellipsis, rank01 클래스, 가수명은 ellipsis, rank02 클래스에 담겨있다.
BeautifulSoup으로 다음과 같이 가져올 수 있다.
response = requests.get(url, headers=headers)
dom_list = BeautifulSoup(response.text, 'html.parser')
elements = dom_list.select('.lst50') # lst50 클래스를 가진 element 전부를 List로 리턴
kpop_50 = [] # DataFrame을 위한 List
for element in elements: # Top50 곡 리스트를 순회
data = {
'song_name' : element.select_one('.rank01').text.replace('\n',''),
'singer' : element.select_one('.rank02 > a').text.replace('\n',''),
}
kpop_50.append(data)
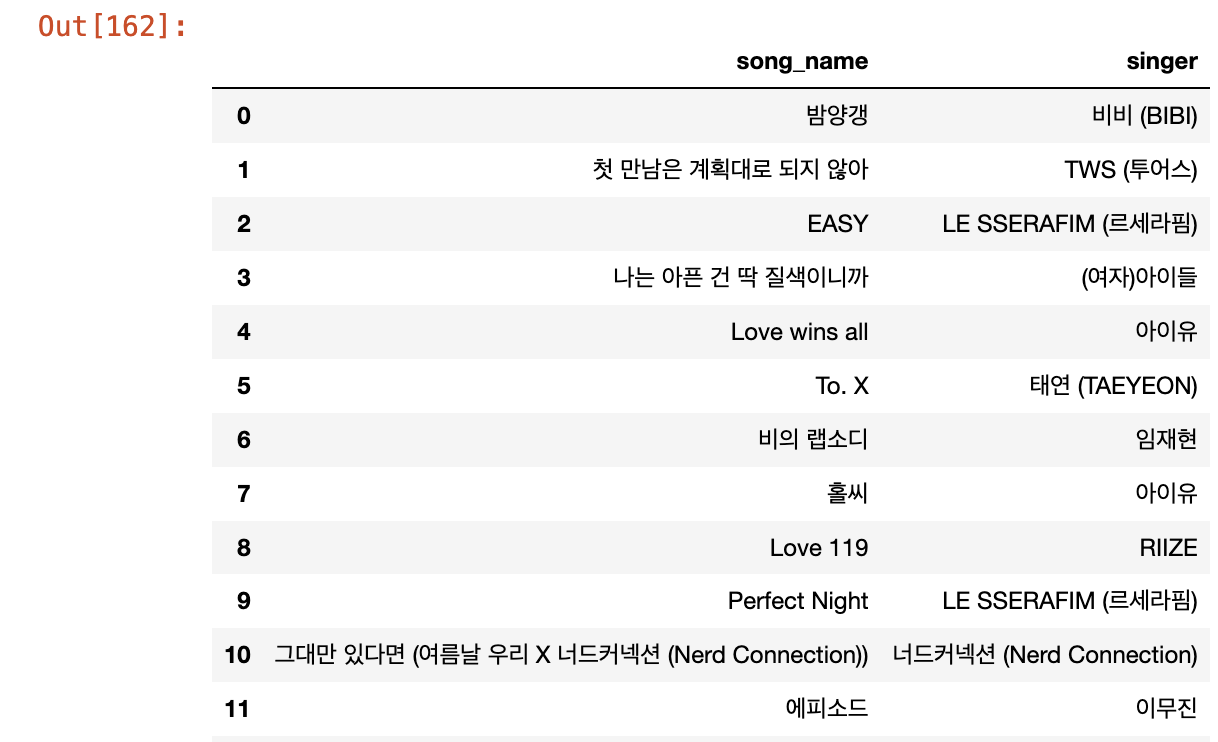
df = pd.DataFrame(kpop_50)
df
Melon 노래 가사 가져오기
같은 방식으로 노래 가사도 가져올 수 있다.
Melon Top 100 클래스를 보면 'data-song-no' 라는 클래스가 존재한다. 8글자로 이루어져 있는데. 이는 각 노래의 상세 정보를 가져올 때 사용하는 각 노래의 ID로 보인다.
따라서 상세 페이지를 보자.
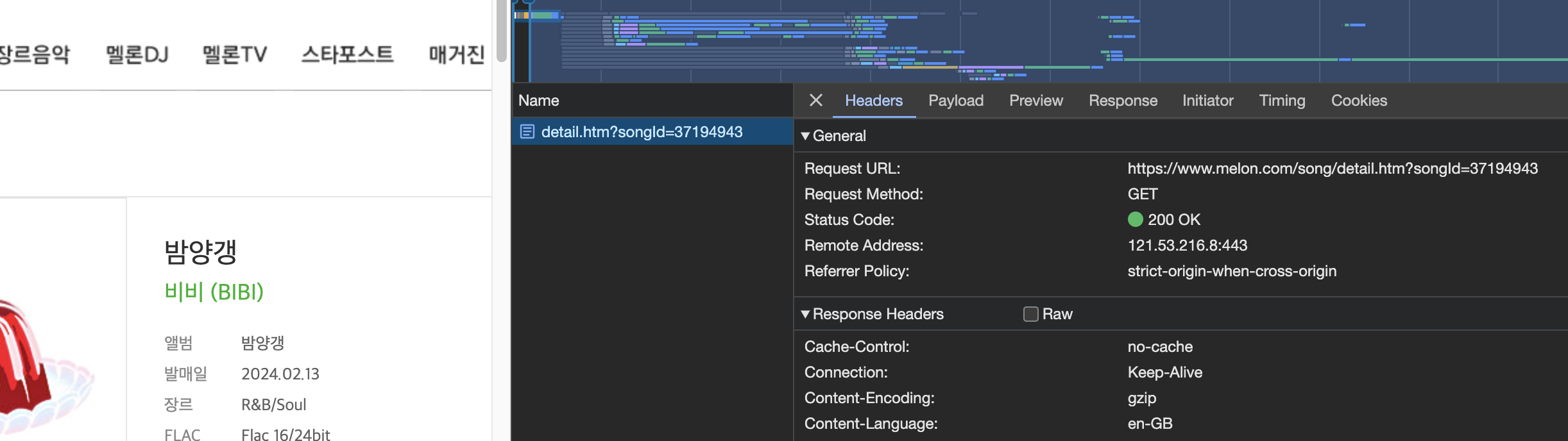
밤양갱의 노래 ID는 37194943으로 확인된다. url에 songId= 뒤로 작성하면 밤양갱 노래의 상세 페이지를 html로 받아 올 수 있다.
song_id = '37194943'
url = f'https://www.melon.com/song/detail.htm?songId={song_id}'
headers = {
'User-Agent': 'User-Agent'
}
url를 지정하고, TOP 100 을 받아올 때와 동일하게 header를 지정한다.
response = requests.get(url, headers=headers)
dom_ly = BeautifulSoup(response.text, 'html.parser')
elements = dom_ly.select('.lyric')[0] # lyric 클래스의 element를 가져온다.
lyrics = str(elements).split('<br/>')[1:-1] # <br/> 태그를 기준으로 리스트 분할
lyrics = [i for i in lyrics if i ] #빈 문자열 제거
lyrics

Top 100 과 가사를 동시에 가져와 보자
response = requests.get(url, headers=headers)
dom_list = BeautifulSoup(response.text, 'html.parser')
elements = dom_list.select('.lst50')
kpop_50 = []
for element in elements:
song_id = element.get('data-song-no')
url = f'https://www.melon.com/song/detail.htm?songId={song_id}'
response = requests.get(url, headers=headers)
dom_ly = BeautifulSoup(response.text, 'html.parser')
lyric = dom_ly.select('.lyric')[0]
lyrics = str(lyric).split('<br/>')[1:-1]
lyrics = [i for i in lyrics if i ]
data = {
'song_name' : element.select_one('.rank01').text.replace('\n',''),
'singer' : element.select_one('.rank02 > a').text.replace('\n',''),
'song_id': song_id,
'lyrics' : lyrics
}
kpop_50.append(data)
df = pd.DataFrame(kpop_50)
df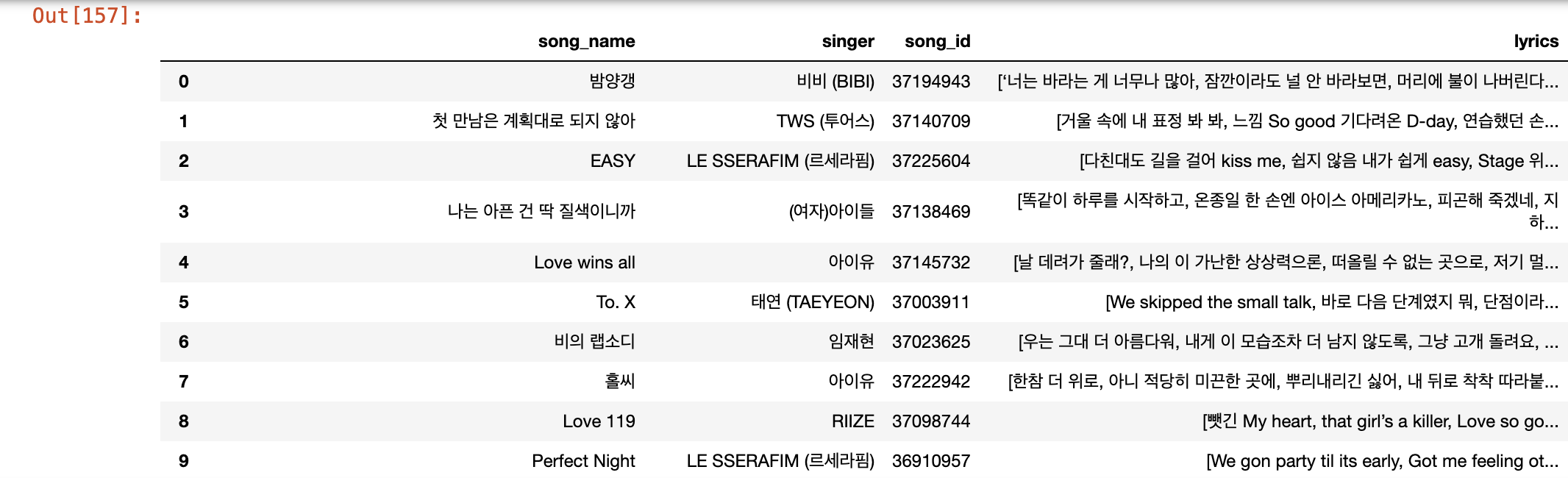
'Python' 카테고리의 다른 글
| (YOLOv8) 위성 영상데이터로 Cool_Roof 분류 - Object detection (0) | 2024.04.13 |
|---|---|
| (Python) 모평균 검정 (t-test, ANOVA) (0) | 2024.02.28 |
| (Python) 평균 추청과 신뢰구간 (모평균 추청, 중심극한정리) (0) | 2024.02.28 |
| Pandas 데이터프레임 Concat(), Merge() (0) | 2024.02.26 |
| Chapter 08. Python Pandas 기초(2) (0) | 2024.02.23 |



