
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- agentic ai
- react agent
- chatGPT
- 에이전트 ai
- 웨크롤링
- AI Agent
- 쳇지피티
- 티스토리챌린지
- 12factorapp
- 티어구조
- LangGraph
- AI 에이전트
- 3티어아키텍처
- AI
- 카나리배포
- 책임분리
- JSON
- 포트바인딩
- 오블완
- API
- MSA
- Python
- xmlschema
- chaosengineering
- 클라우드네이티브
- temurin
- LLM
- ci_cd
- java17
- web crowling
Archives
- Today
- Total
Nacho
(Python) 모평균 검정 (t-test, ANOVA) 본문
반응형
빅분기 시절 공부 했던 이론을 다시 꺼내어 정리해 봤다.

( Feature, x ) : 범주 이고, (Target, y ) : 연속 일 때,
T-test, ANOVA, Wilcoxon, 등등.. 정리가 안돼서 머리 아픈 청춘을 위해하여...

정규성 검사
import spicy.stats as stats
statistic, pvalue = stats.shapiro(df['column'])
단일 표본 t 검정
statistic, p_value = stats.ttest_1samp(df['column'],
popmean= mean,
alternative='greater or less or two-sided')
윌콕슨 부호순위 검정
statistic, pvalue = stats.wilcoxon(df['colums']-mean, alternative='greater or less or two-sided')

대응 표본 t 검정
statistic, pvalue = stats.ttest_rel(df['column1'], df['column2'], alternative='greater or less or two-sided')
윌콕슨 부호순위 검정
statistic, pvalue = stats.wilcoxon(df['column1']-df['column2'], alternative='greater or less or two-sided')
등분산성 검정
statistic, pvalue = stats.bartlett(df['column1'],df['column2'])
독립 표본 t 검정
statistic, pvalue = stats.ttest_ind(df['column1'], df['column2'],
equal_var= True or False, #등분산성
alternative='greater or less or two-sided')
윌콕슨 순위합 검정
statistic, pvalue = stats.ranksums(df['column1'], df['column2'],
alternative='greater or less or two-sided')
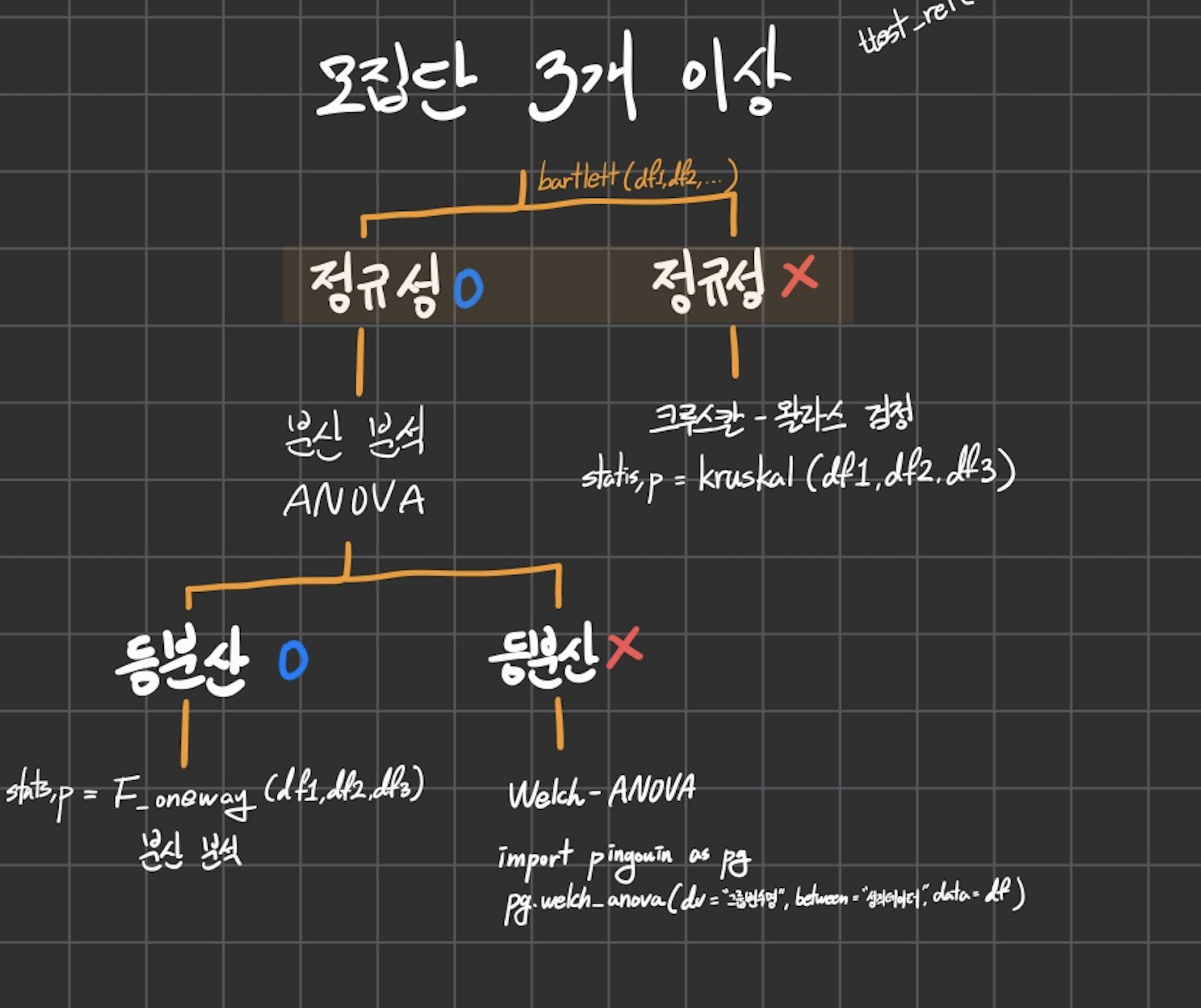
정규성 검정
import spicy.stats as stats
statistic, pvalue = stats.shapiro(df['A'])
statistic, pvalue = stats.shapiro(df['B'])
statistic, pvalue = stats.shapiro(df['C'])
등분산 검정
statisic, pvalue = stats.bartlett(df['A'], df['B'], df['C'])
ANOVA
statistic, pvalue = stats.f_oneway(df['A'], df['B'], df['C'])
크루스칼-왈라스 검정
statistic, pvalue = stats.kruskal(df['A'], df['B'], df['C'])
( Feature, x ) : 범주 이고, (Target, y ) : 범주 일 때,
카이제곱 검정.

정규성 검정
statistic, pvalue = chisquare(f_obs=f_obs, f_exp=f_exp) # 관측빈도, 기대빈도
독립서 검정
statistic, pvalue, dof, expected = chi2_contingency(df)
# 검정통계량, p값, 자유도, 기대빈도반응형
'Python' 카테고리의 다른 글
| (YOLOv8) 위성 영상데이터로 Cool_Roof 분류 - Object detection (0) | 2024.04.13 |
|---|---|
| (Python) Web Crowling 웹크롤링 (멜론 차트 TOP 100) (0) | 2024.03.10 |
| (Python) 평균 추청과 신뢰구간 (모평균 추청, 중심극한정리) (0) | 2024.02.28 |
| Pandas 데이터프레임 Concat(), Merge() (0) | 2024.02.26 |
| Chapter 08. Python Pandas 기초(2) (0) | 2024.02.23 |
'Python' Related Articles
more



